
Today, we’ll see the fusion of Vision Transformer knowledge and Language Model (LLM) expertise. You can extract features and text from the image using Blip-2. In this article, we’ll see the Online Demo of Blip-2 image captioning and how we can use Blip-2 for Image Extraction.
There’s a remarkable technique that’s caught our attention – the Blip-2: Bootstrapping Language Image Pre-Training with Frozen Image Encoders and LLMs.
What is Blip-2?
Blip-2, called Bootstrapping Language Image Pre-Training with Frozen Image Encoders and LLMs, is an innovative technique that connects vision and language models using Transformers.
It serves as a bridge between vision-based understanding and language-based processing, enabling tasks like image captioning, content moderation, multimodal search, and interactive visual question answering.
Blip-2 achieves this by using a Q Format – a specialized Transformer interface that connects vision and language Transformers, allowing for the seamless integration and training of models for enhanced AI capabilities.
Understanding Blip-2: A Bridge Between Vision and Language
Blip-2, introduced in a research paper from Salesforce Research on January 30, 2023, bridges the gap between vision and language, paving the way for exciting applications.
But, you might ask, “What are the practical use cases of this technology?”
- Image Captioning: Enables description of images for visually impaired individuals.
- Content Moderation: Detects inappropriate content beyond just text.
- Image Text Retrieval: Facilitates multimodal search, autonomous driving, and more.
- Visual Question Answering: Allows for interactive Q&A based on images.
The combination of Transformers: Vision & Language
The key lies in understanding the transformative aspect of Transformers in both vision and language models. Whether it’s T5, Flan, or Vision Transformers, the architecture is crucial.

Blip-2’s essence is in connecting these Transformer architectures – a vision Transformer and a language Transformer.
Blip-2 Features:
| Image Captioning | Based on the given image it will provide the caption of the image. |
| Content Moderation | Detects inappropriate content beyond just text. |
| Image Text Retrieval | It can extract the text from the images. |
| Visual Question Answering | Allows for interactive Q&A based on images. |
The Q Format: A Transformer for Bridging Modalities
To address the modality gap between vision and language, the Q Format steps in. It’s the connecting bridge, an interface between vision and language Transformers.
But how does it work?
- The Q Format comprises two modules: an Image Transformer and a Text Transformer.
- Utilizes common self-attention layers within its structure.
The Blip-2 Training Process:
Stage 1: Vision Language Representation Learning
- Connects the Q Format to the Frozen Image Encoder.
- Trains using specific image-text pairs with contrasting and matching loss functions.
Stage 2: Vision Language Generative Learning
- Connects the Q Format to the Frozen LLM (e.g., Flan T5 XXL).
- Involves an image-ground text generation task using causal language model loss.
The beauty of Blip-2 lies in its versatility. It doesn’t confine you to specific models but opens the doors to combine various visual backbones with diverse language models for creating powerful Vision Language Transformers.
Coding the Blip-2 Pipeline: Bringing Theory into Practice
In our next session, we’re delving into the coding part. We’ll walk through the steps, build our own app, and possibly even explore a Gradio implementation.
By the end, we’ll have our operational Vision Language Transformer model ready for use!
How to use Blip-2?
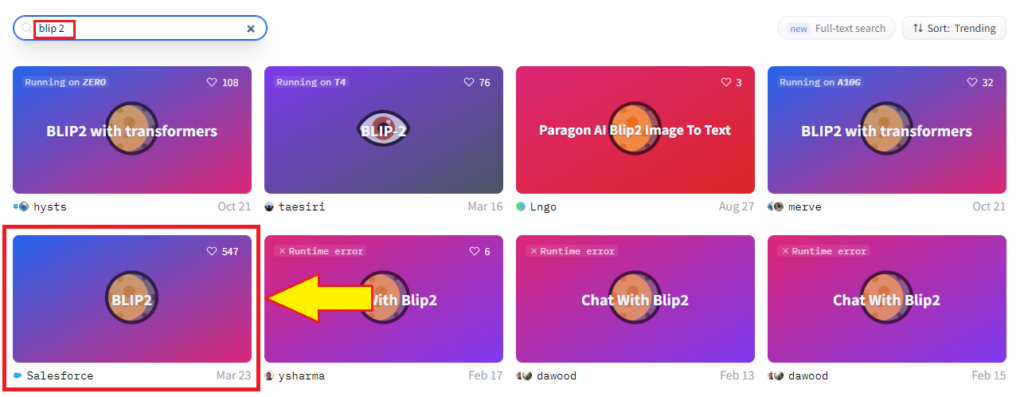
Visit the Hugging Face platform and in spaces search for Blip-2. Click on the Space.
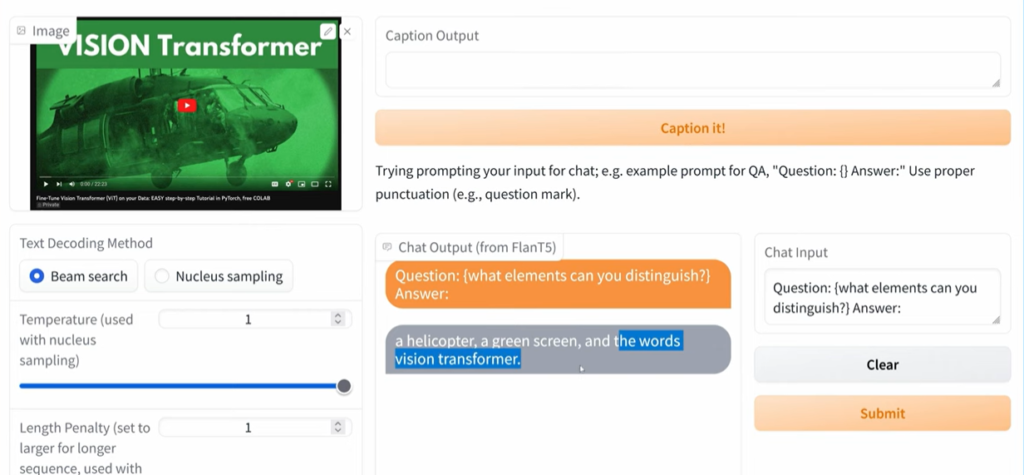
Upload the image and ask questions related to the Image.
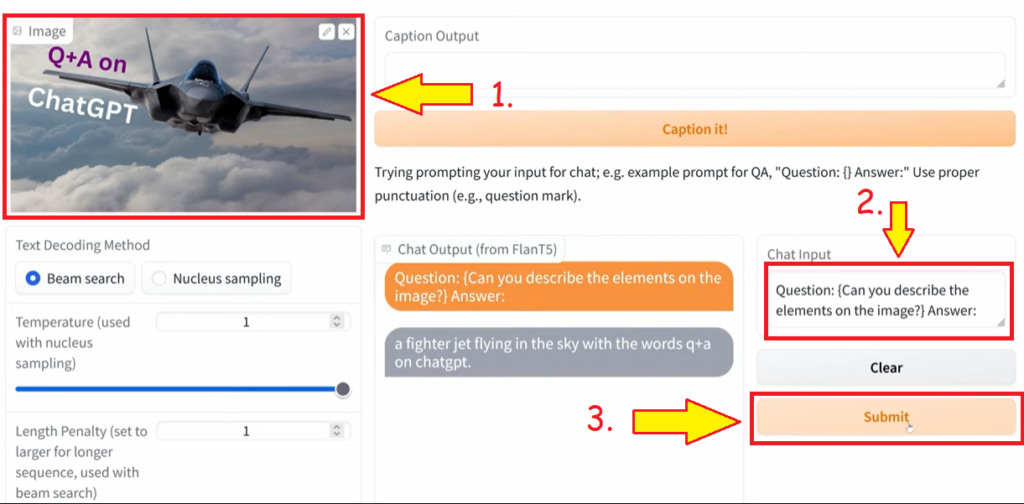
Click on the Submit button.
If you want to generate the caption of the given image, then click on the ‘Caption it‘ button.
How to generate an Image Caption?
Visit the Hugging Face platform > spaces and search for Blip-2 salesforce.
Upload the Image.
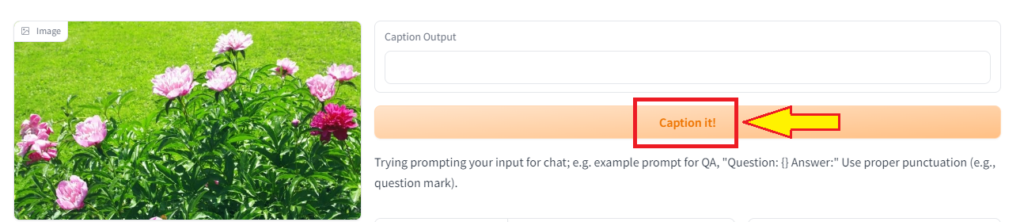
Click on the ‘Caption it‘ button.
Conclusion:
Blip-2 enables you to write captions for images and extract text from images. Imagine feeding an image into a system and receiving correspondingly relevant responses through chat interactions. The capability to provide image descriptions for the visually impaired through image captioning showcases its profound impact on accessibility and inclusivity.



